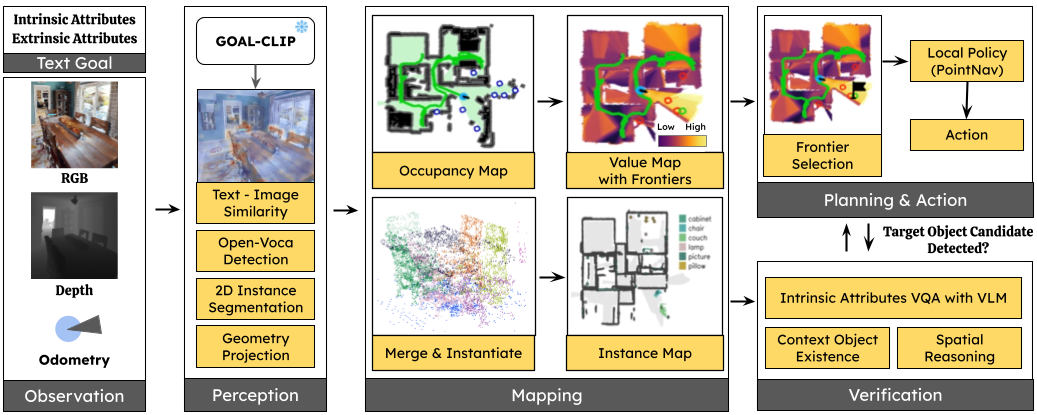
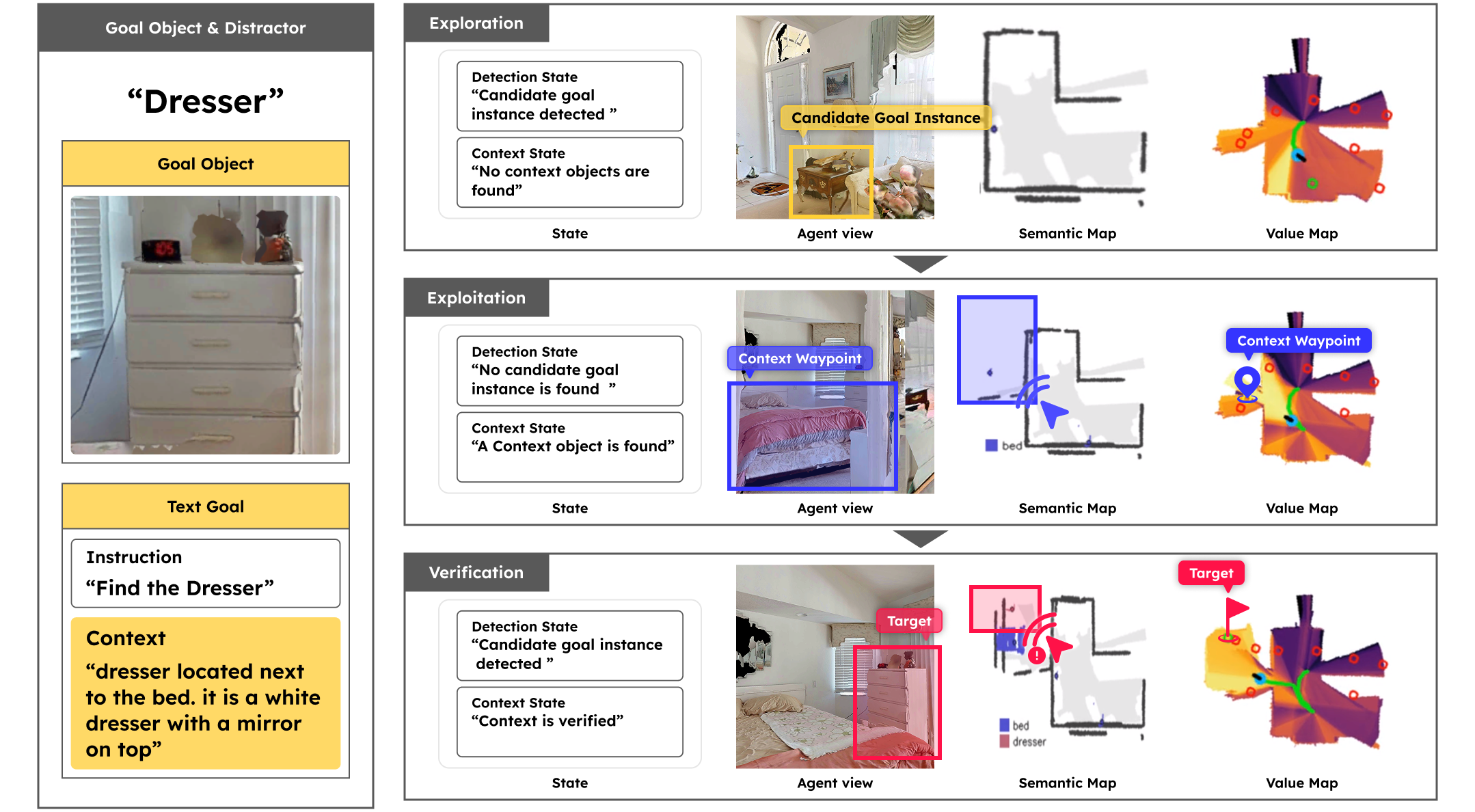
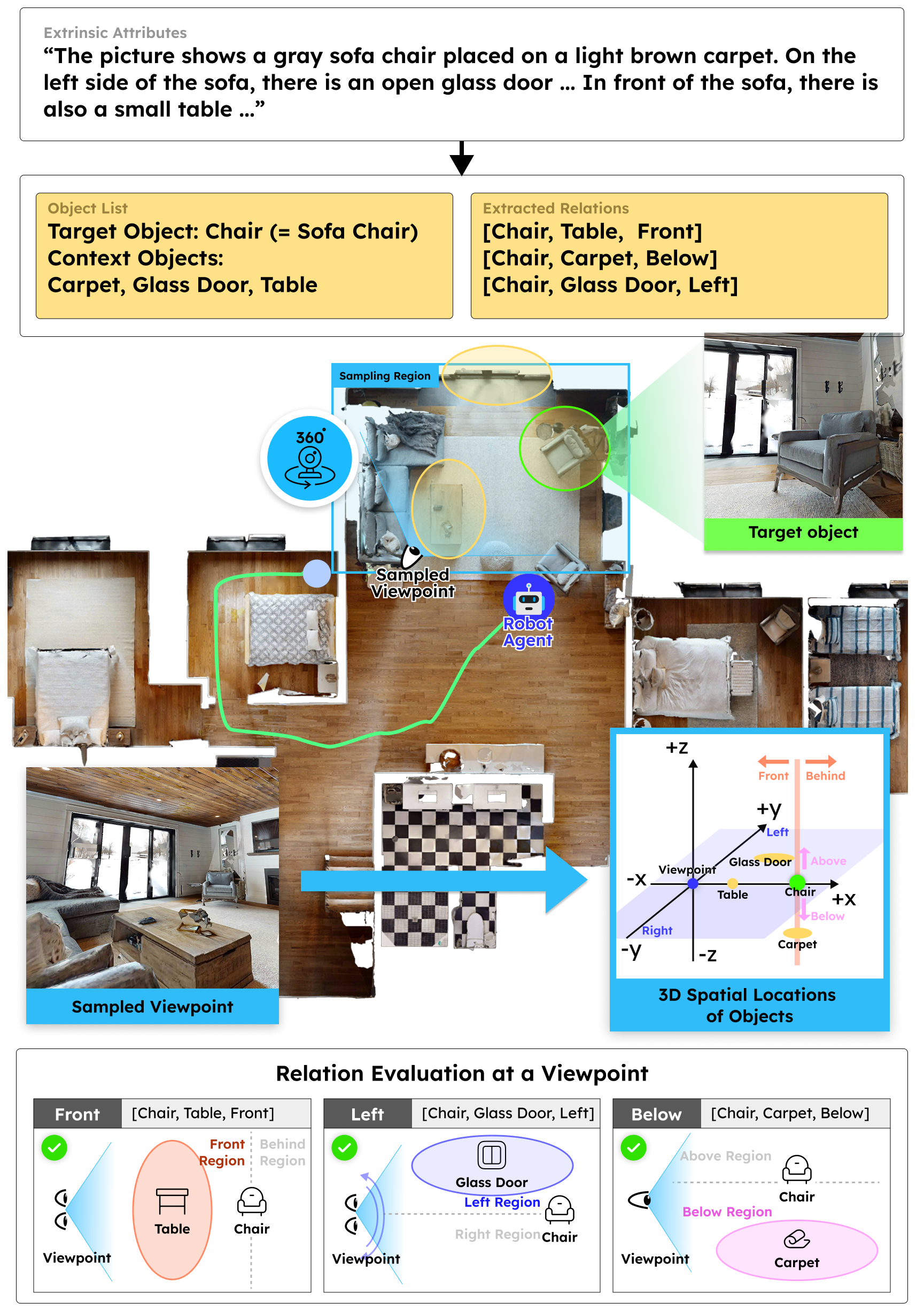
Overview
Most existing TGIN methods reduce long descriptions to a set of object labels or a structured representation, underutilizing the rich contextual information already present in the description. Context-Nav takes a fundamentally different perspective: spatial reasoning is not merely a verification step but a primary exploration signal. Rather than detecting objects and then checking whether they match the description, the agent explores spaces that are contextually consistent with the entire description, and only commits to an instance after explicit 3D spatial verification. Given a description that mixes intrinsic attributes (e.g., "mainly yellow and green") with extrinsic context (e.g., "located above the cabinet and near the staircase"), the agent explores guided by the context-driven value map and rejects early candidates whose color or nearby context objects do not match, ultimately finding the correct instance where 3D verification confirms all constraints are satisfied.

Figure 1. Overview of the text-goal instance navigation task and our context-driven pipeline.